本文主要从源码分析角度来看从0开始扩容和缩容到0的过程。主要核心点在于从0开始扩容,主要涉及activator和autoscaler组件。在了解了从0开始扩容之后,自然就会明白缩容到0的时候发生了什么。
概览
当 Pod 缩容到零的时候流量会指到 Activator 上面,Activator 接收到流量以后会主动“通知”Autoscaler 做一个扩容的操作。扩容完成以后 Activator 需要等待第一个 Pod ready 之后才能把流量转发过来。这里在queue上定义了readinessProbe,通过SERVING_READINESS_PROBE环境变量可以设置queue以指定的方式(exec、tcp、http)探活服务容器是否准备好接收流量。
activator监听endpoints(还记得private的service是设置了label selector的吗,k8s会自动创建对应的endpoint)等待服务pod启动完成后,将流量转发给对应的pod。
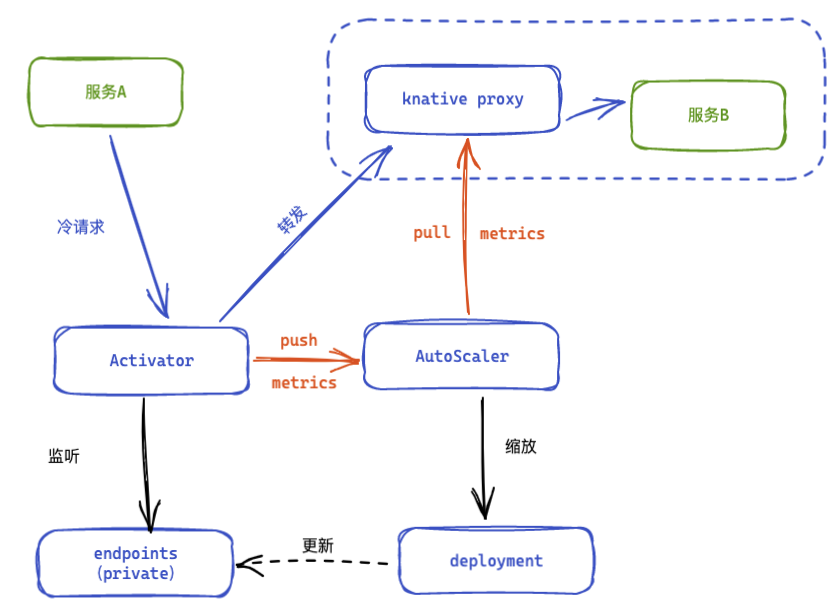
从0扩容Activator源码分析
本部分主要为了梳理当服务为0副本,请求到达activator的代码运行过程,探究其hold住流量,等待pod启动后转发的机制。所以对于其他未涉及在此流程中的代码暂不进行分析。
这个流程中的一些关键节点大概可以整理成下图:
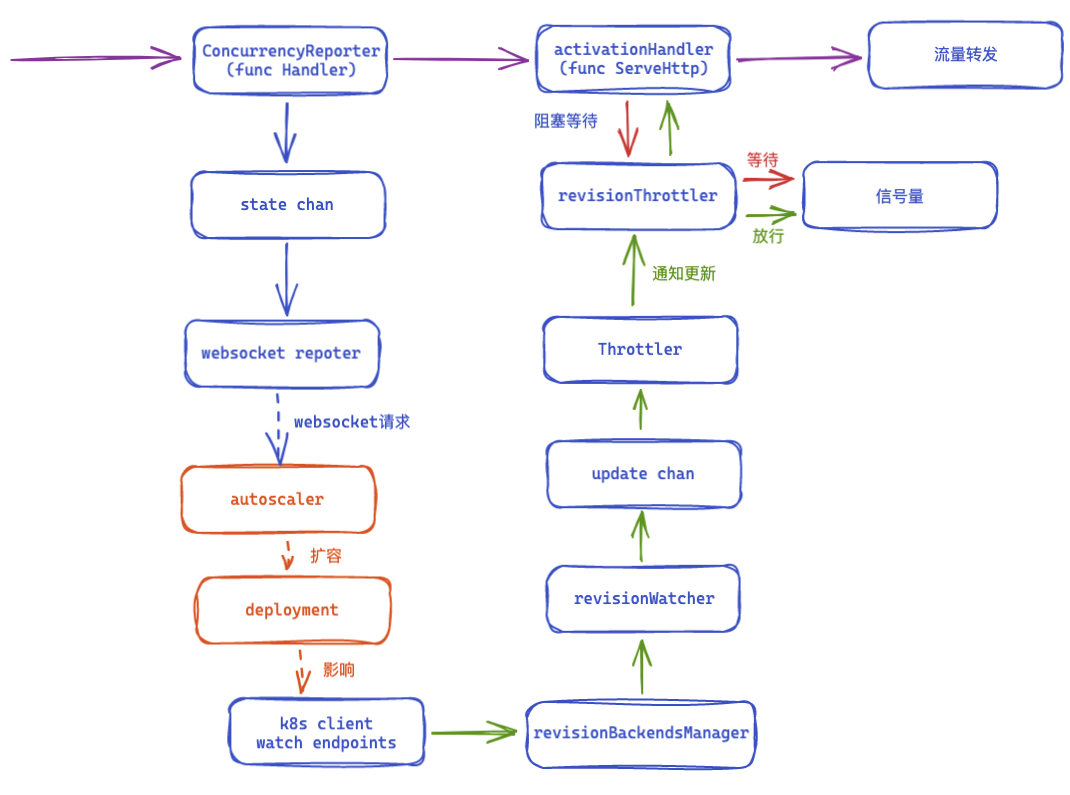
指标上报到autoscaler
目标服务解析
activator从请求 header Knative-Serving-Namespace、Knative-Serving-Revision分别解析出来服务所在的namespace和revision,这两个header值是在定义kingress的时候设置的appendHeaders选项定义的,由网关自动附加。
如果这两个header值任意一个为空,那么就获取访问host,按照${name}.${namespace}.svc.${clusterdomain}的形式尝试解析host获取上述两个值。
然后尝试获取revision的详细定义,并将信息附着到context中。
后续是一系列中间件的处理,其中pkg/activator/handler/tracing_handler.go是trace的处理。
流量指标统计与上报
在pkg/activator/handler/concurrency_reporter.go文件中定义了Handler路由中间件方法,此方法主要是为了统计流量和并发数量,同时也在对应服务没有副本的时候触发向autoscaler上报的行为。
// Handler returns a handler that records requests coming in/being finished in the stats
// machinery.
func (cr *ConcurrencyReporter) Handler(next http.Handler) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
revisionKey := RevIDFrom(r.Context())
stat := cr.handleRequestIn(network.ReqEvent{Key: revisionKey, Type: network.ReqIn, Time: time.Now()})
defer func() {
// 主要是将并发数量-1
cr.handleRequestOut(stat, network.ReqEvent{Key: revisionKey, Type: network.ReqOut, Time: time.Now()})
}()
next.ServeHTTP(w, r)
}
}
handleRequestIn定义在pkg/activator/handler/context_handler.go文件中这个函数中其主要行为就是调用getOrCreateStat函数,如果这个服务没有pod,那么msg就不为nil,而将msg发送到cr.statCh后,最终会通过websocket发送给autoscaler,autoscaler会根据其中的revision信息(namespace + name)来最终触发扩容操作。
接下来是pkg/activator/handler/concurrency_reporter.go的处理,如果是某个服务第一次被请求,那么会将这个信息发到statCh,它的处理在pkg/activator/stat_reporter.go中就是将指标数据结构转换一下,通过vendor中knative.dev/pkg/websocket/connection.go封装的websocket发送到autoscaler中。
// handleRequestIn handles an event of a request coming into the system. Returns the stats
// the outgoing event should be recorded to.
func (cr *ConcurrencyReporter) handleRequestIn(event network.ReqEvent) *revisionStats {
// 只有是第一次请求的时候才会有msg这个信息。后续会发往activator触发扩容。
stat, msg := cr.getOrCreateStat(event)
if msg != nil {
cr.statCh <- []asmetrics.StatMessage{*msg}
}
// 记录并发数量+1,记录请求数量+1.请求结束时也会调用下面逻辑,并发数量会在请求结束时被减掉。
stat.stats.HandleEvent(event)
return stat
}
如果当前map中无revision对应的state,就返回一个StatMessage来将状态上报给autoscaler从而触发从0扩容,这一部分在后面会详细介绍,接下来让我们先继续往下看。如果有对应的state就将refs++。注意这里的一个常见的并发场景使用锁的方式,在第一次取的时候用的读锁,且手动释放。第二次使用写锁,且第一步同样是检查是否存在。
state对应的指标也会通过prometheus指标方式暴露出去,供autoscaler获取。
// getOrCreateStat gets a stat from the state if present.
// If absent it creates a new one and returns it, potentially returning a StatMessage too
// to trigger an immediate scale-from-0.
func (cr *ConcurrencyReporter) getOrCreateStat(event network.ReqEvent) (*revisionStats, *asmetrics.StatMessage) {
cr.mux.RLock()
stat := cr.stats[event.Key]
if stat != nil {
// Since this is incremented under the lock, it's guaranteed to be observed by
// the deletion routine.
stat.refs.Inc()
cr.mux.RUnlock()
return stat, nil
}
cr.mux.RUnlock()
// Doubly checked locking.
cr.mux.Lock()
defer cr.mux.Unlock()
stat = cr.stats[event.Key]
if stat != nil {
// Since this is incremented under the lock, it's guaranteed to be observed by
// the deletion routine.
stat.refs.Inc()
return stat, nil
}
stat = &revisionStats{
stats: network.NewRequestStats(event.Time),
firstRequest: 1,
}
stat.refs.Inc()
cr.stats[event.Key] = stat
return stat, &asmetrics.StatMessage{
// 这里是被请求服务的Namespace和版本Name
Key: event.Key,
Stat: asmetrics.Stat{
// 这个是activator自己的实际pod名称。
PodName: cr.podName,
AverageConcurrentRequests: 1,
// The way the checks are written, this cannot ever be
// anything else but 1. The stats map key is only deleted
// after a reporting period, so we see this code path at most
// once per period.
RequestCount: 1,
},
}
}
阻塞等待扩容完成
实际流量的处理
经过各个中间件流程后,最后走到pkg/activator/handler/handler.go中等待pod启动并转发。主要的等待pod启动的逻辑是在a.throttler.Try中进行处理的。等待pod启动后会调用传入的func
func (a *activationHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
config := activatorconfig.FromContext(r.Context())
tracingEnabled := config.Tracing.Backend != tracingconfig.None
tryContext, trySpan := r.Context(), (*trace.Span)(nil)
if tracingEnabled {
tryContext, trySpan = trace.StartSpan(r.Context(), "throttler_try")
}
revID := RevIDFrom(r.Context())
if err := a.throttler.Try(tryContext, revID, func(dest string) error {
// 当pod被启动后,即会执行此函数的内部逻辑,对请求进行转发
trySpan.End()
proxyCtx, proxySpan := r.Context(), (*trace.Span)(nil)
if tracingEnabled {
proxyCtx, proxySpan = trace.StartSpan(r.Context(), "activator_proxy")
}
a.proxyRequest(revID, w, r.WithContext(proxyCtx), dest, tracingEnabled, a.usePassthroughLb)
proxySpan.End()
return nil
}); err != nil {
// Set error on our capacity waiting span and end it.
trySpan.Annotate([]trace.Attribute{trace.StringAttribute("activator.throttler.error", err.Error())}, "ThrottlerTry")
trySpan.End()
a.logger.Errorw("Throttler try error", zap.String(logkey.Key, revID.String()), zap.Error(err))
if errors.Is(err, context.DeadlineExceeded) || errors.Is(err, queue.ErrRequestQueueFull) {
http.Error(w, err.Error(), http.StatusServiceUnavailable)
} else {
w.WriteHeader(http.StatusInternalServerError)
}
}
}
try函数循环处理一直会等待到pod启动后执行func逻辑。rt.breaker.Maybe是等待pod启动的关键。pod启动后会尝试获取目标地址,并且循环尝试,获取到地址之后,调用传入func,在上面函数中完成对请求的转发。
func (rt *revisionThrottler) try(ctx context.Context, function func(string) error) error {
var ret error
// Retrying infinitely as long as we receive no dest. Outer semaphore and inner
// pod capacity are not changed atomically, hence they can race each other. We
// "reenqueue" requests should that happen.
reenqueue := true
for reenqueue {
reenqueue = false
if err := rt.breaker.Maybe(ctx, func() {
cb, tracker := rt.acquireDest(ctx)
if tracker == nil {
// This can happen if individual requests raced each other or if pod
// capacity was decreased after passing the outer semaphore.
reenqueue = true
return
}
defer cb()
// We already reserved a guaranteed spot. So just execute the passed functor.
ret = function(tracker.dest)
}); err != nil {
return err
}
}
return ret
}
maybe函数主要是检查是否activator hold住的请求数量达到配置上限,如果达到了就直接丢弃。否则调用 b.sem.acquire(ctx)阻塞等待信号量。
// Maybe conditionally executes thunk based on the Breaker concurrency
// and queue parameters. If the concurrency limit and queue capacity are
// already consumed, Maybe returns immediately without calling thunk. If
// the thunk was executed, Maybe returns nil, else error.
func (b *Breaker) Maybe(ctx context.Context, thunk func()) error {
if !b.tryAcquirePending() {
return ErrRequestQueueFull
}
defer b.releasePending()
// Wait for capacity in the active queue.
if err := b.sem.acquire(ctx); err != nil {
return err
}
// Defer releasing capacity in the active.
// It's safe to ignore the error returned by release since we
// make sure the semaphore is only manipulated here and acquire
// + release calls are equally paired.
defer b.sem.release()
// Do the thing.
thunk()
// Report success
return nil
}
在acquire中可以看到其在等待s.queue这个通道。那么是谁向这个通道发送的数据呢?在什么情况下发送的数据?实际上这个通道的数据处理是另外一个协程进行的,在服务副本数为0的时候会初始化这个通道,在服务副本数大于0的时候会直接关闭这个通道。
// acquire acquires capacity from the semaphore.
func (s *semaphore) acquire(ctx context.Context) error {
for {
old := s.state.Load()
capacity, in := unpack(old)
if in >= capacity {
select {
case <-ctx.Done():
return ctx.Err()
case <-s.queue:
}
// Force reload state.
continue
}
in++
if s.state.CAS(old, pack(capacity, in)) {
return nil
}
}
}
感知副本数量变化
副本数量变化处理
由于服务副本数量变化是通过k8s client监听的,通过通道传递。这里先解析在副本数量变动后如何处理,如何向上文中的通道发送数据。
在监听到revision对应的endpoint资源信息有变动的时候,会将信息进行一定处理以后发送到updateCh。在启动activator的时候会调用此Throttler的run方法来处理状态变化。这里在监听的变化的时候直接交给了handleUpdate函数来处理。
func (t *Throttler) run(updateCh <-chan revisionDestsUpdate) {
for {
select {
case update, ok := <-updateCh:
if !ok {
t.logger.Info("The Throttler has stopped.")
return
}
t.handleUpdate(update)
case eps := <-t.epsUpdateCh:
t.handlePubEpsUpdate(eps)
}
}
}
Throttler的handleUpdate主要就是创建或者获取revisioin对应的revisionThrottler然后转到pkg/activator/net/throttler.go中的revisionThrottler来处理副本数和
func (rt *revisionThrottler) handleUpdate(update revisionDestsUpdate) {
rt.logger.Debugw("Handling update",
zap.String("ClusterIP", update.ClusterIPDest), zap.Object("dests", logging.StringSet(update.Dests)))
// ClusterIP is not yet ready, so we want to send requests directly to the pods.
// NB: this will not be called in parallel, thus we can build a new podTrackers
// array before taking out a lock.
if update.ClusterIPDest == "" {
// Create a map for fast lookup of existing trackers.
trackersMap := make(map[string]*podTracker, len(rt.podTrackers))
for _, tracker := range rt.podTrackers {
trackersMap[tracker.dest] = tracker
}
trackers := make([]*podTracker, 0, len(update.Dests))
// Loop over dests, reuse existing tracker if we have one, otherwise create
// a new one.
for newDest := range update.Dests {
tracker, ok := trackersMap[newDest]
if !ok {
if rt.containerConcurrency == 0 {
tracker = newPodTracker(newDest, nil)
} else {
tracker = newPodTracker(newDest, queue.NewBreaker(queue.BreakerParams{
QueueDepth: breakerQueueDepth,
MaxConcurrency: rt.containerConcurrency,
InitialCapacity: rt.containerConcurrency, // Presume full unused capacity.
}))
}
}
trackers = append(trackers, tracker)
}
rt.updateThrottlerState(len(update.Dests), trackers, nil /*clusterIP*/)
return
}
rt.updateThrottlerState(len(update.Dests), nil /*trackers*/, newPodTracker(update.ClusterIPDest, nil))
}
updateThrottlerState函数就是计算实际pod数量,然后调用rt.updateCapacity来更新pod数量。
func (rt *revisionThrottler) updateThrottlerState(backendCount int, trackers []*podTracker, clusterIPDest *podTracker) {
rt.logger.Infof("Updating Revision Throttler with: clusterIP = %v, trackers = %d, backends = %d",
clusterIPDest, len(trackers), backendCount)
// Update trackers / clusterIP before capacity. Otherwise we can race updating our breaker when
// we increase capacity, causing a request to fall through before a tracker is added, causing an
// incorrect LB decision.
if func() bool {
rt.mux.Lock()
defer rt.mux.Unlock()
rt.podTrackers = trackers
rt.clusterIPTracker = clusterIPDest
return clusterIPDest != nil || len(trackers) > 0
}() {
// If we have an address to target, then pass through an accurate
// accounting of the number of backends.
rt.updateCapacity(backendCount)
} else {
// If we do not have an address to target, then we should treat it
// as though we have zero backends.
rt.updateCapacity(0)
}
}
updateCapacity最终根据pod数量计算出可以放行的最大请求数(即pod数量 * 每个pod允许并发数 / activator数量),然后调用Breaker的UpdateConcurrency函数(还记得这个breaker吗,这就是上文中hold住流量等待信号量的breaker),它调用了自己的信号量的UpdateConcurrency来最终通知到那些在阻塞等待的请求。
// updateCapacity updates the capacity of the throttler and recomputes
// the assigned trackers to the Activator instance.
// Currently updateCapacity is ensured to be invoked from a single go routine
// and this does not synchronize
func (rt *revisionThrottler) updateCapacity(backendCount int) {
// We have to make assignments on each updateCapacity, since if number
// of activators changes, then we need to rebalance the assignedTrackers.
ac, ai := int(rt.numActivators.Load()), int(rt.activatorIndex.Load())
numTrackers := func() int {
// We do not have to process the `podTrackers` under lock, since
// updateCapacity is guaranteed to be executed by a single goroutine.
// But `assignedTrackers` is being read by the serving thread, so the
// actual assignment has to be done under lock.
// We're using cluster IP.
if rt.clusterIPTracker != nil {
return 0
}
// Sort, so we get more or less stable results.
sort.Slice(rt.podTrackers, func(i, j int) bool {
return rt.podTrackers[i].dest < rt.podTrackers[j].dest
})
assigned := rt.podTrackers
if rt.containerConcurrency > 0 {
rt.resetTrackers()
assigned = assignSlice(rt.podTrackers, ai, ac, rt.containerConcurrency)
}
rt.logger.Debugf("Trackers %d/%d: assignment: %v", ai, ac, assigned)
// The actual write out of the assigned trackers has to be under lock.
rt.mux.Lock()
defer rt.mux.Unlock()
rt.assignedTrackers = assigned
return len(assigned)
}()
capacity := 0
if numTrackers > 0 {
// Capacity is computed based off of number of trackers,
// when using pod direct routing.
capacity = rt.calculateCapacity(len(rt.podTrackers), ac)
} else {
// Capacity is computed off of number of ready backends,
// when we are using clusterIP routing.
capacity = rt.calculateCapacity(backendCount, ac)
}
rt.logger.Infof("Set capacity to %d (backends: %d, index: %d/%d)",
capacity, backendCount, ai, ac)
rt.backendCount = backendCount
rt.breaker.UpdateConcurrency(capacity)
}
// UpdateConcurrency updates the maximum number of in-flight requests.
func (b *Breaker) UpdateConcurrency(size int) {
b.sem.updateCapacity(size)
}
可以看到这里就是向s.queue发送了指定数量的数据,以放行这些流量。(// todo 这个时候pod扩缩容了会是什么情况)
// updateCapacity updates the capacity of the semaphore to the desired size.
func (s *semaphore) updateCapacity(size int) {
s64 := uint64(size)
for {
old := s.state.Load()
capacity, in := unpack(old)
if capacity == s64 {
// Nothing to do, exit early.
return
}
if s.state.CAS(old, pack(s64, in)) {
if s64 > capacity {
for i := uint64(0); i < s64-capacity; i++ {
select {
case s.queue <- struct{}{}:
default:
// See comment in `release` for explanation of this case.
}
}
}
return
}
}
}
监听副本数量变化
˙重点监听revision状态变化逻辑在pkg/activator/net/revision_backends.go定义。在去掉一些其他逻辑后,从下面可以看出在newRevisionBackendsManagerWithProbeFrequency函数中定义了对private service对应的endpoint的监听。Throttler的Run函数将监听到的变化和上文中副本数量变化的处理部分衔接起来。update channle中发送的是revision信息(name和namespace)。
前面说过对于revision和其endpoint的监听是在pkg/activator/net/revision_backends.go文件中定义的。会监听revision和endpoint资源。在revision有变动的时候,todo。主要是要监听endpoint资源的变动,在增加和删除的时候会调用update函数,传入当前的endpoint信息:
监听变动,筛选条件为带有revisionUID标签,并且必须是private的
// Run starts the throttler and blocks until the context is done.
func (t *Throttler) Run(ctx context.Context, probeTransport http.RoundTripper, usePassthroughLb bool, meshMode network.MeshCompatibilityMode) {
rbm := newRevisionBackendsManager(ctx, probeTransport, usePassthroughLb, meshMode)
// Update channel is closed when ctx is done.
t.run(rbm.updates())
}
func newRevisionBackendsManager(ctx context.Context, tr http.RoundTripper, usePassthroughLb bool, meshMode network.MeshCompatibilityMode) *revisionBackendsManager {
return newRevisionBackendsManagerWithProbeFrequency(ctx, tr, usePassthroughLb, meshMode, defaultProbeFrequency)
}
func newRevisionBackendsManagerWithProbeFrequency(ctx context.Context, tr http.RoundTripper,
usePassthroughLb bool, meshMode network.MeshCompatibilityMode, probeFreq time.Duration) *revisionBackendsManager {
rbm := &revisionBackendsManager{
// ...
}
endpointsInformer := endpointsinformer.Get(ctx)
endpointsInformer.Informer().AddEventHandler(cache.FilteringResourceEventHandler{
FilterFunc: reconciler.ChainFilterFuncs(
reconciler.LabelExistsFilterFunc(serving.RevisionUID),
// We are only interested in the private services, since that is
// what is populated by the actual revision backends.
reconciler.LabelFilterFunc(networking.ServiceTypeKey, string(networking.ServiceTypePrivate), false),
),
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: rbm.endpointsUpdated,
UpdateFunc: controller.PassNew(rbm.endpointsUpdated),
DeleteFunc: rbm.endpointsDeleted,
},
})
// ...
return rbm
}
在监听到endpoint被添加和修改后的实际处理函数逻辑为:获取RevisionWatcher将ready的和notReady的pod信息发送到其destsCh中:
// endpointsUpdated is a handler function to be used by the Endpoints informer.
// It updates the endpoints in the RevisionBackendsManager if the hosts changed
func (rbm *revisionBackendsManager) endpointsUpdated(newObj interface{}) {
// Ignore the updates when we've terminated.
select {
case <-rbm.ctx.Done():
return
default:
}
endpoints := newObj.(*corev1.Endpoints)
revID := types.NamespacedName{Namespace: endpoints.Namespace, Name: endpoints.Labels[serving.RevisionLabelKey]}
rw, err := rbm.getOrCreateRevisionWatcher(revID)
if err != nil {
rbm.logger.Errorw("Failed to get revision watcher", zap.Error(err), zap.String(logkey.Key, revID.String()))
return
}
ready, notReady := endpointsToDests(endpoints, pkgnet.ServicePortName(rw.protocol))
select {
case <-rbm.ctx.Done():
return
case rw.destsCh <- dests{ready: ready, notReady: notReady}:
}
}
revision watcher在被创建的时候会起协程运行run函数,每当通道内有消息的时候会将信息进行处理并交由checkDests进一步处理,最终在这个函数中交由sendUpdate将更新信息发到update channel中,这个channel就是一开始提到的。
删除部分辅助逻辑后,可以清晰看到此函数功能就是当destsCh新的dest到来的时候,就将之前的和现在的一起交由sendUpdate处理。
func (rw *revisionWatcher) run(probeFrequency time.Duration) {
defer close(rw.done)
var curDests, prevDests dests
for {
select {
case <-rw.stopCh:
return
case x := <-rw.destsCh:
rw.logger.Debugf("Updating Endpoints: ready backends: %d, not-ready backends: %d", len(x.ready), len(x.notReady))
prevDests, curDests = curDests, x
}
rw.checkDests(curDests, prevDests)
}
}
checkDests函数首先查看是否是缩容到0,如果是就直接发送pod已经缩容到0的通知逻辑。这一块逻辑稍微有点复杂,但是目标很简单,就是将现在这个服务的clusterIP和pod访问地址交由sendUpdate进一步处理。而sendUpdate就是将数据封装一下加上revision信息发送到update 通道。从而触发了上面副本变化的处理逻辑。
// checkDests performs probing and potentially sends a dests update. It is
// assumed this method is not called concurrently.
func (rw *revisionWatcher) checkDests(curDests, prevDests dests) {
// 缩容到0后的处理
if len(curDests.ready) == 0 && len(curDests.notReady) == 0 {
// We must have scaled down.
rw.clusterIPHealthy = false
rw.healthyPods = nil
rw.logger.Debug("ClusterIP is no longer healthy.")
// Send update that we are now inactive (both params invalid).
rw.sendUpdate("", nil)
return
}
// If we have discovered (or have been told via meshMode) that this revision
// cannot be probed directly do not spend time trying.
if rw.podsAddressable && rw.meshMode != network.MeshCompatibilityModeEnabled {
// reprobe set contains the targets that moved from ready to non-ready set.
// so they have to be re-probed.
reprobe := curDests.becameNonReady(prevDests)
if len(reprobe) > 0 {
rw.logger.Infow("Need to reprobe pods who became non-ready",
zap.Object("IPs", logging.StringSet(reprobe)))
// Trim the pods that migrated to the non-ready set from the
// ready set from the healthy pods. They will automatically
// probed below.
for p := range reprobe {
rw.healthyPods.Delete(p)
}
}
// First check the pod IPs. If we can individually address
// the Pods we should go that route, since it permits us to do
// precise load balancing in the throttler.
hs, noop, notMesh, err := rw.probePodIPs(curDests.ready, curDests.notReady)
if err != nil {
rw.logger.Warnw("Failed probing pods", zap.Object("curDests", curDests), zap.Error(err))
// We dont want to return here as an error still affects health states.
}
// We need to send update if reprobe is non-empty, since the state
// of the world has been changed.
rw.logger.Debugf("Done probing, got %d healthy pods", len(hs))
if !noop || len(reprobe) > 0 {
rw.healthyPods = hs
// Note: it's important that this copies (via hs.Union) the healthy pods
// set before sending the update to avoid concurrent modifications
// affecting the throttler, which iterates over the set.
rw.sendUpdate("" /*clusterIP*/, hs.Union(nil))
return
}
// no-op, and we have successfully probed at least one pod.
if len(hs) > 0 {
return
}
// We didn't get any pods, but we know the mesh is not enabled since we got
// a non-mesh status code while probing, so we don't want to fall back.
if notMesh {
return
}
}
if rw.usePassthroughLb {
// If passthrough lb is enabled we do not want to fall back to going via the
// clusterIP and instead want to exit early.
return
}
if rw.meshMode == network.MeshCompatibilityModeDisabled {
// If mesh is disabled we always want to use direct pod addressing, and
// will not fall back to clusterIP.
return
}
// If we failed to probe even a single pod, check the clusterIP.
// NB: We can't cache the IP address, since user might go rogue
// and delete the K8s service. We'll fix it, but the cluster IP will be different.
dest, err := rw.getDest()
if err != nil {
rw.logger.Errorw("Failed to determine service destination", zap.Error(err))
return
}
// If cluster IP is healthy and we haven't scaled down, short circuit.
if rw.clusterIPHealthy {
rw.logger.Debugf("ClusterIP %s already probed (ready backends: %d)", dest, len(curDests.ready))
rw.sendUpdate(dest, curDests.ready)
return
}
// If clusterIP is healthy send this update and we are done.
if ok, err := rw.probeClusterIP(dest); err != nil {
rw.logger.Errorw("Failed to probe clusterIP "+dest, zap.Error(err))
} else if ok {
// We can reach here only iff pods are not successfully individually probed
// but ClusterIP conversely has been successfully probed.
rw.podsAddressable = false
rw.logger.Debugf("ClusterIP is successfully probed: %s (ready backends: %d)", dest, len(curDests.ready))
rw.clusterIPHealthy = true
rw.healthyPods = nil
rw.sendUpdate(dest, curDests.ready)
}
}
func (rw *revisionWatcher) sendUpdate(clusterIP string, dests sets.String) {
select {
case <-rw.stopCh:
return
default:
rw.updateCh <- revisionDestsUpdate{Rev: rw.rev, ClusterIPDest: clusterIP, Dests: dests}
}
}
endpoint的修改是由k8s自动触发的。
从0扩容autoscaler源码分析
接收activator从0扩容指标
首先让我们把目光聚焦到接收activator 发送的metrics并进行处理的逻辑。statserver启动一个websocket服务器,接收activator在服务没有副本的时候发送的流量参数,标志着这个服务需要立即从0扩容。这里通过statsCh将指标的接收与处理解耦开来。
func main() {
// ......
// autoscaler在接收到从websocket上报的指标后,会把消息内容发送到这个通道中进行异步处理。
// statsCh is the main communication channel between the stats server and multiscaler.
statsCh := make(chan asmetrics.StatMessage, statsBufferLen)
defer close(statsCh)
// ......
// accept is the func to call when this pod owns the Revision for this StatMessage.
// 实际有了请求之后,冷启动时发送过来的信息
accept := func(sm asmetrics.StatMessage) {
// 这个就是将指标发给统计的,在计算扩缩容状态的时候就会用到这些指标
collector.Record(sm.Key, time.Unix(sm.Stat.Timestamp, 0), sm.Stat)
multiScaler.Poke(sm.Key, sm.Stat)
}
var f *statforwarder.Forwarder
if b, bs, err := leaderelection.NewStatefulSetBucketAndSet(int(cc.Buckets)); err == nil {
logger.Info("Running with StatefulSet leader election")
ctx = leaderelection.WithStatefulSetElectorBuilder(ctx, cc, b)
f = statforwarder.New(ctx, bs)
if err := statforwarder.StatefulSetBasedProcessor(ctx, f, accept); err != nil {
logger.Fatalw("Failed to set up statefulset processors", zap.Error(err))
}
} else {
logger.Info("Running with Standard leader election")
ctx = leaderelection.WithStandardLeaderElectorBuilder(ctx, kubeClient, cc)
f = statforwarder.New(ctx, bucket.AutoscalerBucketSet(cc.Buckets))
if err := statforwarder.LeaseBasedProcessor(ctx, f, accept); err != nil {
logger.Fatalw("Failed to set up lease tracking", zap.Error(err))
}
}
// Set up a statserver.
statsServer := statserver.New(statsServerAddr, statsCh, logger, f.IsBucketOwner)
defer f.Cancel()
go controller.StartAll(ctx, controllers...)
go func() {
for sm := range statsCh {
// Set the timestamp when first receiving the stat.
if sm.Stat.Timestamp == 0 {
sm.Stat.Timestamp = time.Now().Unix()
}
f.Process(sm)
}
}()
profilingServer := profiling.NewServer(profilingHandler)
eg, egCtx := errgroup.WithContext(ctx)
eg.Go(statsServer.ListenAndServe)
eg.Go(profilingServer.ListenAndServe)
}
上面可以看到指标都是由Process函数进行处理的。这个函数是将消息发往一个内部通道,获取processor并在其process函数中进行处理并执行重试逻辑,最大重试次数是硬编码的30次,每次重试间隔500ms。注意一点是autoscaler处于主节点和从节点模式下processor的处理逻辑是不同的。如果是从节点的话,就把这个消息再发到主节点的websocket端口上去,然后主节点的逻辑又会走到这里,所以后面主要以当前autoscaler是主节点情况下分析。
// Process enqueues the given Stat for processing asynchronously.
// It calls Forwarder.accept if the pod where this Forwarder is running is the owner
// of the given StatMessage. Otherwise it forwards the given StatMessage to the right
// owner pod. It will retry if any error happens during the processing.
func (f *Forwarder) Process(sm asmetrics.StatMessage) {
f.statCh <- stat{sm: sm, retry: 0}
}
func (f *Forwarder) process() {
defer func() {
f.retryWg.Wait()
f.processingWg.Done()
}()
for {
select {
case <-f.stopCh:
return
case s := <-f.statCh:
rev := s.sm.Key.String()
l := f.logger.With(zap.String(logkey.Key, rev))
bkt := f.bs.Owner(rev)
// 获取processor,由于高可用情况下存在多个autoscaler副本,但是只有一个能处理。所以processor也有两种类型
p := f.getProcessor(bkt)
if p == nil {
l.Warn("Can't find the owner for Revision bucket: ", bkt)
f.maybeRetry(l, s)
continue
}
if err := p.process(s.sm); err != nil {
l.Errorw("Error while processing stat", zap.Error(err))
f.maybeRetry(l, s)
}
}
}
}
这里看下process的处理,就是调用了之前main函数中定义的accept,做了两件事情一个是记录指标,指标记录是一个单独的逻辑会在后面介绍。一个是调用multiScaler.Poke这个方法,接下来看下这个方法做了什么。
func (p *localProcessor) process(sm asmetrics.StatMessage) error {
l := p.logger.With(zap.String(logkey.Key, sm.Key.String()))
l.Debug("Accept stat as owner of bucket ", p.bkt)
p.accept(sm)
return nil
}
// accept 对应在main函数中定义的函数,传递进来的
accept := func(sm asmetrics.StatMessage) {
// 这个就是将指标发给统计的,在计算扩缩容状态的时候就会用到这些指标
collector.Record(sm.Key, time.Unix(sm.Stat.Timestamp, 0), sm.Stat)
multiScaler.Poke(sm.Key, sm.Stat)
}
这个函数的作用就是检查是否立即触发扩容。如果目前副本数是0,但是并发数不为0,就要立即从0扩容,就将信号发送到revision对应的scaler的pokeCh通道中。
// 这个函数的作用就是检查是否立即触发扩容
// Poke checks if the autoscaler needs to be run immediately.
func (m *MultiScaler) Poke(key types.NamespacedName, stat metrics.Stat) {
m.scalersMutex.RLock()
defer m.scalersMutex.RUnlock()
scaler, exists := m.scalers[key]
if !exists {
return
}
if scaler.latestScale() == 0 && stat.AverageConcurrentRequests != 0 {
scaler.pokeCh <- struct{}{}
}
}
触发扩缩容
对pokeCh处理的核心逻辑定义在pkg/autoscaler/scaling/multiscaler.go文件中,可以看到计算扩缩容的操作会被周期触发,或者在pokeCh有数据时立即触发。扩缩容处理函数tickScaler就是获取
func (m *MultiScaler) runScalerTicker(runner *scalerRunner, metricKey types.NamespacedName) {
ticker := m.tickProvider(tickInterval)
go func() {
defer ticker.Stop()
for {
select {
case <-m.scalersStopCh:
return
case <-runner.stopCh:
return
case <-ticker.C:
m.tickScaler(runner.scaler, runner, metricKey)
case <-runner.pokeCh:
m.tickScaler(runner.scaler, runner, metricKey)
}
}
}()
}
func (m *MultiScaler) tickScaler(scaler UniScaler, runner *scalerRunner, metricKey types.NamespacedName) {
// scaler.Scale是一个比较复杂的函数,其主要作用就是计算期望副本数。其返回值结构体如下:
//type ScaleResult struct {
// 期望副本数.
// DesiredPodCount int32
// 是考虑到目标突发容量的修正后的满负荷容量.
// ExcessBurstCapacity int32
// 这个结果是否有用
// ScaleValid bool
//}
sr := scaler.Scale(runner.logger, time.Now())
if !sr.ScaleValid {
return
}
// scalerRunner也是一个非常核心的struct,这里主要就是将计算结构更新到自己的结构体内部字段。特别是期望副本数,在其他地方想要取期望副本数的时候,就通过此结构体取。
if runner.updateLatestScale(sr) {
m.Inform(metricKey)
}
}
Scale的定义在pkg/autoscaler/scaling/autoscaler.go文件中。如果你觉得太长你就大概理解为这个函数根据activator和queue上报上来的指标计算期望副本数就行了。具体在下面函数中关键点都有注释
// Scale calculates the desired scale based on current statistics given the current time.
// desiredPodCount is the calculated pod count the autoscaler would like to set.
// validScale signifies whether the desiredPodCount should be applied or not.
// Scale is not thread safe in regards to panic state, but it's thread safe in
// regards to acquiring the decider spec.
func (a *autoscaler) Scale(logger *zap.SugaredLogger, now time.Time) ScaleResult {
desugared := logger.Desugar()
debugEnabled := desugared.Core().Enabled(zapcore.DebugLevel)
// 获取缩放配置
spec := a.currentSpec()
// 获取ready的pod的数量
originalReadyPodsCount, err := a.podCounter.ReadyCount()
// If the error is NotFound, then presume 0.
if err != nil && !apierrors.IsNotFound(err) {
logger.Errorw("Failed to get ready pod count via K8S Lister", zap.Error(err))
return invalidSR
}
// Use 1 if there are zero current pods.
readyPodsCount := math.Max(1, float64(originalReadyPodsCount))
metricKey := types.NamespacedName{Namespace: a.namespace, Name: a.revision}
metricName := spec.ScalingMetric
var observedStableValue, observedPanicValue float64
// 对应两种扩容模式:并发数RPS、每秒请求数concurrency
switch spec.ScalingMetric {
case autoscaling.RPS:
observedStableValue, observedPanicValue, err = a.metricClient.StableAndPanicRPS(metricKey, now)
default:
metricName = autoscaling.Concurrency // concurrency is used by default
observedStableValue, observedPanicValue, err = a.metricClient.StableAndPanicConcurrency(metricKey, now)
}
if err != nil {
if errors.Is(err, metrics.ErrNoData) {
logger.Debug("No data to scale on yet")
} else {
logger.Errorw("Failed to obtain metrics", zap.Error(err))
}
return invalidSR
}
// 根据获取的指标数据计算需要的pod数量
// Make sure we don't get stuck with the same number of pods, if the scale up rate
// is too conservative and MaxScaleUp*RPC==RPC, so this permits us to grow at least by a single
// pod if we need to scale up.
// E.g. MSUR=1.1, OCC=3, RPC=2, TV=1 => OCC/TV=3, MSU=2.2 => DSPC=2, while we definitely, need
// 3 pods. See the unit test for this scenario in action.
maxScaleUp := math.Ceil(spec.MaxScaleUpRate * readyPodsCount)
// Same logic, opposite math applies here.
maxScaleDown := 0.
if spec.Reachable {
maxScaleDown = math.Floor(readyPodsCount / spec.MaxScaleDownRate)
}
dspc := math.Ceil(observedStableValue / spec.TargetValue)
dppc := math.Ceil(observedPanicValue / spec.TargetValue)
if debugEnabled {
desugared.Debug(
fmt.Sprintf("For metric %s observed values: stable = %0.3f; panic = %0.3f; target = %0.3f "+
"Desired StablePodCount = %0.0f, PanicPodCount = %0.0f, ReadyEndpointCount = %d, MaxScaleUp = %0.0f, MaxScaleDown = %0.0f",
metricName, observedStableValue, observedPanicValue, spec.TargetValue,
dspc, dppc, originalReadyPodsCount, maxScaleUp, maxScaleDown))
}
// We want to keep desired pod count in the [maxScaleDown, maxScaleUp] range.
desiredStablePodCount := int32(math.Min(math.Max(dspc, maxScaleDown), maxScaleUp))
desiredPanicPodCount := int32(math.Min(math.Max(dppc, maxScaleDown), maxScaleUp))
isOverPanicThreshold := dppc/readyPodsCount >= spec.PanicThreshold
if a.panicTime.IsZero() && isOverPanicThreshold {
// Begin panicking when we cross the threshold in the panic window.
logger.Info("PANICKING.")
a.panicTime = now
pkgmetrics.Record(a.reporterCtx, panicM.M(1))
} else if isOverPanicThreshold {
// If we're still over panic threshold right now — extend the panic window.
a.panicTime = now
} else if !a.panicTime.IsZero() && !isOverPanicThreshold && a.panicTime.Add(spec.StableWindow).Before(now) {
// Stop panicking after the surge has made its way into the stable metric.
logger.Info("Un-panicking.")
a.panicTime = time.Time{}
a.maxPanicPods = 0
pkgmetrics.Record(a.reporterCtx, panicM.M(0))
}
desiredPodCount := desiredStablePodCount
if !a.panicTime.IsZero() {
// In some edgecases stable window metric might be larger
// than panic one. And we should provision for stable as for panic,
// so pick the larger of the two.
if desiredPodCount < desiredPanicPodCount {
desiredPodCount = desiredPanicPodCount
}
logger.Debug("Operating in panic mode.")
// We do not scale down while in panic mode. Only increases will be applied.
if desiredPodCount > a.maxPanicPods {
logger.Infof("Increasing pods count from %d to %d.", originalReadyPodsCount, desiredPodCount)
a.maxPanicPods = desiredPodCount
} else if desiredPodCount < a.maxPanicPods {
logger.Infof("Skipping pod count decrease from %d to %d.", a.maxPanicPods, desiredPodCount)
}
desiredPodCount = a.maxPanicPods
} else {
logger.Debug("Operating in stable mode.")
}
// Delay scale down decisions, if a ScaleDownDelay was specified.
// We only do this if there's a non-nil delayWindow because although a
// one-element delay window is _almost_ the same as no delay at all, it is
// not the same in the case where two Scale()s happen in the same time
// interval (because the largest will be picked rather than the most recent
// in that case).
if a.delayWindow != nil {
a.delayWindow.Record(now, desiredPodCount)
delayedPodCount := a.delayWindow.Current()
if delayedPodCount != desiredPodCount {
if debugEnabled {
desugared.Debug(
fmt.Sprintf("Delaying scale to %d, staying at %d",
desiredPodCount, delayedPodCount))
}
desiredPodCount = delayedPodCount
}
}
// Compute excess burst capacity
//
// the excess burst capacity is based on panic value, since we don't want to
// be making knee-jerk decisions about Activator in the request path.
// Negative EBC means that the deployment does not have enough capacity to serve
// the desired burst off hand.
// EBC = TotCapacity - Cur#ReqInFlight - TargetBurstCapacity
excessBCF := -1.
switch {
case spec.TargetBurstCapacity == 0:
excessBCF = 0
case spec.TargetBurstCapacity > 0:
totCap := float64(originalReadyPodsCount) * spec.TotalValue
excessBCF = math.Floor(totCap - spec.TargetBurstCapacity - observedPanicValue)
}
if debugEnabled {
desugared.Debug(fmt.Sprintf("PodCount=%d Total1PodCapacity=%0.3f ObsStableValue=%0.3f ObsPanicValue=%0.3f TargetBC=%0.3f ExcessBC=%0.3f",
originalReadyPodsCount, spec.TotalValue, observedStableValue,
observedPanicValue, spec.TargetBurstCapacity, excessBCF))
}
switch spec.ScalingMetric {
case autoscaling.RPS:
pkgmetrics.RecordBatch(a.reporterCtx,
excessBurstCapacityM.M(excessBCF),
desiredPodCountM.M(int64(desiredPodCount)),
stableRPSM.M(observedStableValue),
panicRPSM.M(observedStableValue),
targetRPSM.M(spec.TargetValue),
)
default:
pkgmetrics.RecordBatch(a.reporterCtx,
excessBurstCapacityM.M(excessBCF),
desiredPodCountM.M(int64(desiredPodCount)),
stableRequestConcurrencyM.M(observedStableValue),
panicRequestConcurrencyM.M(observedPanicValue),
targetRequestConcurrencyM.M(spec.TargetValue),
)
}
return ScaleResult{
DesiredPodCount: desiredPodCount,
ExcessBurstCapacity: int32(excessBCF),
ScaleValid: true,
}
}
我们简单看下在计算出缩放信息后updateLatestScale做的事情,这个函数的返回就是标志者是否要放到事件队列中触发下游的更新。这个函数的作用就是将副本信息放到sr.decider.Status中。decider看起来本来是一种k8s资源后来发现只需要存在内存中就可以了。
func (sr *scalerRunner) updateLatestScale(sRes ScaleResult) bool {
ret := false
sr.mux.Lock()
defer sr.mux.Unlock()
if sr.decider.Status.DesiredScale != sRes.DesiredPodCount {
sr.decider.Status.DesiredScale = sRes.DesiredPodCount
ret = true
}
// If sign has changed -- then we have to update KPA.
ret = ret || !sameSign(sr.decider.Status.ExcessBurstCapacity, sRes.ExcessBurstCapacity)
// Update with the latest calculation anyway.
sr.decider.Status.ExcessBurstCapacity = sRes.ExcessBurstCapacity
return ret
}
然后调用Inform函数,这里的watcher函数就是将此事件通知到workQueue来进行后续处理。
// Inform sends an update to the registered watcher function, if it is set.
func (m *MultiScaler) Inform(event types.NamespacedName) bool {
m.watcherMutex.RLock()
defer m.watcherMutex.RUnlock()
if m.watcher != nil {
m.watcher(event)
return true
}
return false
}
// 上面函数中的m.watcher就是对应此函数,在pkg/reconciler/autoscaling/kpa/controller.go文件`NewController`函数中被赋值的
// EnqueueKey takes a namespace/name string and puts it onto the work queue.
func (c *Impl) EnqueueKey(key types.NamespacedName) {
c.workQueue.Add(key)
if logger := c.logger.Desugar(); logger.Core().Enabled(zapcore.DebugLevel) {
logger.Debug(fmt.Sprintf("Adding to queue %s (depth: %d)", safeKey(key), c.workQueue.Len()),
zap.String(logkey.Key, key.String()))
}
}
Worker queue的内容最终会在processNextWorkItem函数中消费。这个函数就是一个集散中心是个通用的函数,每个crd都会有一个对应的controller实例,这里核心就是对c.Reconciler.Reconcile函数的调用,这个函数会根据具体情况决定后续执行ReconcileKind还是销毁后的清理还是观察。在当前情况下会转到kpa对应的ReconcileKind函数。
// processNextWorkItem will read a single work item off the workqueue and
// attempt to process it, by calling Reconcile on our Reconciler.
func (c *Impl) processNextWorkItem() bool {
obj, shutdown := c.workQueue.Get()
if shutdown {
return false
}
key := obj.(types.NamespacedName)
keyStr := safeKey(key)
c.logger.Debugf("Processing from queue %s (depth: %d)", safeKey(key), c.workQueue.Len())
startTime := time.Now()
// Send the metrics for the current queue depth
c.statsReporter.ReportQueueDepth(int64(c.workQueue.Len()))
var err error
defer func() {
status := trueString
if err != nil {
status = falseString
}
c.statsReporter.ReportReconcile(time.Since(startTime), status, key)
// We call Done here so the workqueue knows we have finished
// processing this item. We also must remember to call Forget if
// reconcile succeeds. If a transient error occurs, we do not call
// Forget and put the item back to the queue with an increased
// delay.
c.workQueue.Done(key)
}()
// Embed the key into the logger and attach that to the context we pass
// to the Reconciler.
logger := c.logger.With(zap.String(logkey.TraceID, uuid.NewString()), zap.String(logkey.Key, keyStr))
ctx := logging.WithLogger(context.Background(), logger)
// Run Reconcile, passing it the namespace/name string of the
// resource to be synced.
// 这个函数主要是根据节点是否是leader及是否是删除事件决定需要应用的函数是什么
if err = c.Reconciler.Reconcile(ctx, keyStr); err != nil {
c.handleErr(logger, err, key, startTime)
return true
}
// Finally, if no error occurs we Forget this item so it does not
// have any delay when another change happens.
c.workQueue.Forget(key)
logger.Infow("Reconcile succeeded", zap.Duration("duration", time.Since(startTime)))
return true
}
后续会调用kpa(以实际缩放类型为准,如果缩放类型是kpa的话)的ReconcileKind,这个函数比较长,我们划一下重点:ReconcileSKS、reconcileDecider、ReconcileMetric、want, err := c.scaler.scale(ctx, pa, sks, decider.Status.DesiredScale)、computeStatus.其中 ReconcileSKS、reconcileDecider、ReconcileMetric都是对对应crd的更新,只有一个例外Decider它不是个实实在在创建到k8s的crd。其中computeStatus其实也是对crd的更新,只不过是更新PodAutoscaler.那么到目前还没有提到的want, err := c.scaler.scale(ctx, pa, sks, decider.Status.DesiredScale)函数就是做了实际对deployment进行缩放的逻辑。
func (c *Reconciler) ReconcileKind(ctx context.Context, pa *autoscalingv1alpha1.PodAutoscaler) pkgreconciler.Event {
ctx, cancel := context.WithTimeout(ctx, 10*time.Second)
defer cancel()
logger := logging.FromContext(ctx)
// We need the SKS object in order to optimize scale to zero
// performance. It is OK if SKS is nil at this point.
sksName := anames.SKS(pa.Name)
sks, err := c.SKSLister.ServerlessServices(pa.Namespace).Get(sksName)
if err != nil && !errors.IsNotFound(err) {
logger.Warnw("Error retrieving SKS for Scaler", zap.Error(err))
}
// Having an SKS and its PrivateServiceName is a prerequisite for all upcoming steps.
if sks == nil || sks.Status.PrivateServiceName == "" {
// Before we can reconcile decider and get real number of activators
// we start with default of 2.
if _, err = c.ReconcileSKS(ctx, pa, nv1alpha1.SKSOperationModeServe, minActivators); err != nil {
return fmt.Errorf("error reconciling SKS: %w", err)
}
pa.Status.MarkSKSNotReady(noPrivateServiceName) // In both cases this is true.
computeStatus(ctx, pa, podCounts{want: scaleUnknown}, logger)
return nil
}
pa.Status.MetricsServiceName = sks.Status.PrivateServiceName
decider, err := c.reconcileDecider(ctx, pa)
if err != nil {
return fmt.Errorf("error reconciling Decider: %w", err)
}
if err := c.ReconcileMetric(ctx, pa, resolveScrapeTarget(ctx, pa)); err != nil {
return fmt.Errorf("error reconciling Metric: %w", err)
}
// Get the appropriate current scale from the metric, and right size
// the scaleTargetRef based on it.
want, err := c.scaler.scale(ctx, pa, sks, decider.Status.DesiredScale)
if err != nil {
return fmt.Errorf("error scaling target: %w", err)
}
// 这里开始计算sks的模式应该是什么,当pod正常的时候就serve模式。模式代表的含义?
mode := nv1alpha1.SKSOperationModeServe
// We put activator in the serving path in the following cases:
// 1. The revision is scaled to 0:
// a. want == 0
// b. want == -1 && PA is inactive (Autoscaler has no previous knowledge of
// this revision, e.g. after a restart) but PA status is inactive (it was
// already scaled to 0).
// 2. The excess burst capacity is negative.
if want == 0 || decider.Status.ExcessBurstCapacity < 0 || want == scaleUnknown && pa.Status.IsInactive() {
mode = nv1alpha1.SKSOperationModeProxy
}
// 根据reversion label获取所有的pod,根据每个pod的状态计算每种状态的pod有多少个。
// Compare the desired and observed resources to determine our situation.
podCounter := resourceutil.NewPodAccessor(c.podsLister, pa.Namespace, pa.Labels[serving.RevisionLabelKey])
ready, notReady, pending, terminating, err := podCounter.PodCountsByState()
if err != nil {
return fmt.Errorf("error getting pod counts: %w", err)
}
// numActivators就是activator的数量
// Determine the amount of activators to put into the routing path.
numActivators := computeNumActivators(ready, decider)
logger.Infof("SKS should be in %s mode: want = %d, ebc = %d, #act's = %d PA Inactive? = %v",
mode, want, decider.Status.ExcessBurstCapacity, numActivators,
pa.Status.IsInactive())
// 创建或者更新sks
sks, err = c.ReconcileSKS(ctx, pa, mode, numActivators)
if err != nil {
return fmt.Errorf("error reconciling SKS: %w", err)
}
// Propagate service name.
pa.Status.ServiceName = sks.Status.ServiceName
// If SKS is not ready — ensure we're not becoming ready.
if sks.IsReady() {
logger.Debug("SKS is ready, marking SKS status ready")
pa.Status.MarkSKSReady()
} else {
logger.Debug("SKS is not ready, marking SKS status not ready")
pa.Status.MarkSKSNotReady(sks.Status.GetCondition(nv1alpha1.ServerlessServiceConditionReady).GetMessage())
}
logger.Infof("PA scale got=%d, want=%d, desiredPods=%d ebc=%d", ready, want,
decider.Status.DesiredScale, decider.Status.ExcessBurstCapacity)
pc := podCounts{
want: int(want),
ready: ready,
notReady: notReady,
pending: pending,
terminating: terminating,
}
logger.Infof("Observed pod counts=%#v", pc)
computeStatus(ctx, pa, pc, logger)
return nil
}
ReconcileMetric定义在pkg/reconciler/autoscaling/reconciler.go文件中。根据kpa和scaler配置计算出目标metrics的crd。在配置没有变更的情况下,不会有更新,所以这个函数在大多数情况下是不会变动的。
// ReconcileMetric reconciles a metric instance out of the given PodAutoscaler to control metric collection.
func (c *Base) ReconcileMetric(ctx context.Context, pa *autoscalingv1alpha1.PodAutoscaler, metricSN string) error {
desiredMetric := resources.MakeMetric(pa, metricSN, config.FromContext(ctx).Autoscaler)
metric, err := c.MetricLister.Metrics(desiredMetric.Namespace).Get(desiredMetric.Name)
if errors.IsNotFound(err) {
_, err = c.Client.AutoscalingV1alpha1().Metrics(desiredMetric.Namespace).Create(ctx, desiredMetric, metav1.CreateOptions{})
if err != nil {
return fmt.Errorf("error creating metric: %w", err)
}
} else if err != nil {
return fmt.Errorf("error fetching metric: %w", err)
} else if !metav1.IsControlledBy(metric, pa) {
pa.Status.MarkResourceNotOwned("Metric", desiredMetric.Name)
return fmt.Errorf("PA: %s does not own Metric: %s", pa.Name, desiredMetric.Name)
} else if !equality.Semantic.DeepEqual(desiredMetric.Spec, metric.Spec) {
want := metric.DeepCopy()
want.Spec = desiredMetric.Spec
if _, err = c.Client.AutoscalingV1alpha1().Metrics(desiredMetric.Namespace).Update(ctx, want, metav1.UpdateOptions{}); err != nil {
return fmt.Errorf("error updating metric: %w", err)
}
}
return nil
}
scale定义在pkg/reconciler/autoscaling/kpa/scaler.go中,功能是对目标进行缩放,主要是计算各种边界状态,并根据实际情况调用缩容到0和进行缩放的函数。
// scale attempts to scale the given PA's target reference to the desired scale.
func (ks *scaler) scale(ctx context.Context, pa *autoscalingv1alpha1.PodAutoscaler, sks *nv1a1.ServerlessService, desiredScale int32) (int32, error) {
asConfig := config.FromContext(ctx).Autoscaler
logger := logging.FromContext(ctx)
if desiredScale < 0 && !pa.Status.IsActivating() {
logger.Debug("Metrics are not yet being collected.")
return desiredScale, nil
}
min, max := pa.ScaleBounds(asConfig)
initialScale := kparesources.GetInitialScale(asConfig, pa)
// Log reachability as quoted string, since default value is "".
logger.Debugf("MinScale = %d, MaxScale = %d, InitialScale = %d, DesiredScale = %d Reachable = %q",
min, max, initialScale, desiredScale, pa.Spec.Reachability)
// If initial scale has been attained, ignore the initialScale altogether.
if initialScale > 1 && !pa.Status.IsScaleTargetInitialized() {
// Ignore initial scale if minScale >= initialScale.
if min < initialScale {
logger.Debugf("Adjusting min to meet the initial scale: %d -> %d", min, initialScale)
}
min = intMax(initialScale, min)
}
if newScale := applyBounds(min, max, desiredScale); newScale != desiredScale {
logger.Debugf("Adjusting desiredScale to meet the min and max bounds before applying: %d -> %d", desiredScale, newScale)
desiredScale = newScale
}
desiredScale, shouldApplyScale := ks.handleScaleToZero(ctx, pa, sks, desiredScale)
if !shouldApplyScale {
return desiredScale, nil
}
// 获取deployment
ps, err := resources.GetScaleResource(pa.Namespace, pa.Spec.ScaleTargetRef, ks.listerFactory)
if err != nil {
return desiredScale, fmt.Errorf("failed to get scale target %v: %w", pa.Spec.ScaleTargetRef, err)
}
currentScale := int32(1)
if ps.Spec.Replicas != nil {
currentScale = *ps.Spec.Replicas
}
if desiredScale == currentScale {
return desiredScale, nil
}
logger.Infof("Scaling from %d to %d", currentScale, desiredScale)
return desiredScale, ks.applyScale(ctx, pa, desiredScale, ps)
}
对deployment副本数进行修改
执行缩容到0的逻辑,todo仔细看看需要缩容到0的时候的逻辑判断
func (ks *scaler) handleScaleToZero(ctx context.Context, pa *autoscalingv1alpha1.PodAutoscaler,
sks *nv1a1.ServerlessService, desiredScale int32) (int32, bool) {
if desiredScale != 0 {
return desiredScale, true
}
// We should only scale to zero when three of the following conditions are true:
// a) enable-scale-to-zero from configmap is true
// b) The PA has been active for at least the stable window, after which it
// gets marked inactive, and
// c) the PA has been backed by the Activator for at least the grace period
// of time.
// Alternatively, if (a) and the revision did not succeed to activate in
// `activationTimeout` time -- also scale it to 0.
cfgs := config.FromContext(ctx)
cfgAS := cfgs.Autoscaler
if !cfgAS.EnableScaleToZero {
return 1, true
}
cfgD := cfgs.Deployment
activationTimeout := cfgD.ProgressDeadline + activationTimeoutBuffer
now := time.Now()
logger := logging.FromContext(ctx)
switch {
case pa.Status.IsActivating(): // Active=Unknown
// If we are stuck activating for longer than our progress deadline, presume we cannot succeed and scale to 0.
if pa.Status.CanFailActivation(now, activationTimeout) {
logger.Info("Activation has timed out after ", activationTimeout)
return desiredScale, true
}
ks.enqueueCB(pa, activationTimeout)
return scaleUnknown, false
case pa.Status.IsActive(): // Active=True
// Don't scale-to-zero if the PA is active
// but return `(0, false)` to mark PA inactive, instead.
sw := aresources.StableWindow(pa, cfgAS)
af := pa.Status.ActiveFor(now)
if af >= sw {
// If SKS is in proxy mode, then there is high probability
// of SKS not changing its spec/status and thus not triggering
// a new reconciliation of PA.
if sks.Spec.Mode == nv1a1.SKSOperationModeProxy {
logger.Debug("SKS is already in proxy mode, auto-re-enqueue PA")
// Long enough to ensure current iteration is finished.
ks.enqueueCB(pa, 3*time.Second)
}
logger.Info("Can deactivate PA, was active for ", af)
return desiredScale, false
}
// Otherwise, scale down to at most 1 for the remainder of the idle period and then
// reconcile PA again.
logger.Infof("Sleeping additionally for %v before can scale to 0", sw-af)
ks.enqueueCB(pa, sw-af)
return 1, true
default: // Active=False
var (
err error
r = true
)
if resolveTBC(ctx, pa) != -1 {
// if TBC is -1 activator is guaranteed to already be in the path.
// Otherwise, probe to make sure Activator is in path.
r, err = ks.activatorProbe(pa, ks.transport)
logger.Infof("Probing activator = %v, err = %v", r, err)
}
if r {
// This enforces that the revision has been backed by the Activator for at least
// ScaleToZeroGracePeriod time.
// And at least ScaleToZeroPodRetentionPeriod since PA became inactive.
// Most conservative check, if it passes we're good.
lastPodTimeout := lastPodRetention(pa, cfgAS)
lastPodMaxTimeout := durationMax(cfgAS.ScaleToZeroGracePeriod, lastPodTimeout)
// If we have been inactive for this long, we can scale to 0!
if pa.Status.InactiveFor(now) >= lastPodMaxTimeout {
return desiredScale, true
}
// Now check last pod retention timeout. Since it's a hard deadline, regardless
// of network programming state we should circle back after that time period.
if lastPodTimeout > 0 {
if inactiveTime := pa.Status.InactiveFor(now); inactiveTime < lastPodTimeout {
logger.Infof("Can't scale to 0; InactiveFor %v < ScaleToZeroPodRetentionPeriod = %v",
inactiveTime, lastPodTimeout)
ks.enqueueCB(pa, lastPodTimeout-inactiveTime)
return desiredScale, false
}
logger.Debug("Last pod timeout satisfied")
}
// Otherwise check how long SKS was in proxy mode.
// Compute the difference between time we've been proxying with the timeout.
// If it's positive, that's the time we need to sleep, if negative -- we
// can scale to zero.
pf := sks.Status.ProxyFor()
to := cfgAS.ScaleToZeroGracePeriod - pf
if to <= 0 {
logger.Info("Fast path scaling to 0, in proxy mode for: ", pf)
return desiredScale, true
}
// Re-enqueue the PA for reconciliation with timeout of `to` to make sure we wait
// long enough.
logger.Info("Enqueueing PA after ", to)
ks.enqueueCB(pa, to)
return desiredScale, false
}
// Otherwise (any prober failure) start the async probe.
logger.Info("PA is not yet backed by activator, cannot scale to zero")
if !ks.probeManager.Offer(context.Background(), paToProbeTarget(pa), pa, probePeriod, probeTimeout, probeOptions...) {
logger.Info("Probe for revision is already in flight")
}
return desiredScale, false
}
}
应用缩放,其核心的逻辑就是根据PodAutoscaler引用的deployment数据gvr,创建修改副本数量的patch来修改对应的deployment。
ScaleTargetRef指向的是deployment,获取dep应用计算出来的patch,其中patch的内容就是将deployment的Replicas数量改为希望的数量,然后进行patch。patchBytes的一个例子:[{"op":"replace","path":"/spec/replicas","value":0}]
func (ks *scaler) applyScale(ctx context.Context, pa *autoscalingv1alpha1.PodAutoscaler, desiredScale int32,
ps *autoscalingv1alpha1.PodScalable) error {
logger := logging.FromContext(ctx)
// 获取引用的deployment
gvr, name, err := resources.ScaleResourceArguments(pa.Spec.ScaleTargetRef)
if err != nil {
return err
}
psNew := ps.DeepCopy()
psNew.Spec.Replicas = &desiredScale
patch, err := duck.CreatePatch(ps, psNew)
if err != nil {
return err
}
patchBytes, err := patch.MarshalJSON()
if err != nil {
return err
}
_, err = ks.dynamicClient.Resource(*gvr).Namespace(pa.Namespace).Patch(ctx, ps.Name, types.JSONPatchType,
patchBytes, metav1.PatchOptions{})
if err != nil {
return fmt.Errorf("failed to apply scale %d to scale target %s: %w", desiredScale, name, err)
}
logger.Debug("Successfully scaled to ", desiredScale)
return nil
}
参考资料: